 luky.util.StringHelper
luky.util.StringHelper
|
Luky Library - 4.1.1 (20061117-1148) | |||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | |||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | |||||||||
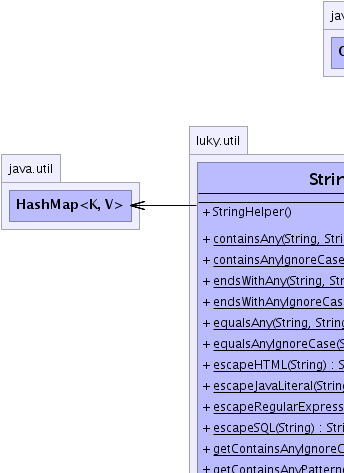
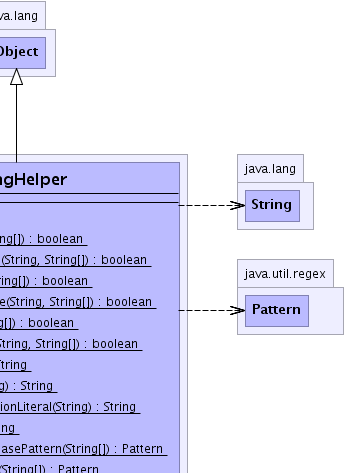
java.lang.Object
public class StringHelper
Utilities for String formatting, manipulation, and queries. More information about this class is available from ostermiller.org.
 |
 |
 |
 |
| Constructor Summary | |
|---|---|
StringHelper()
|
|
| Method Summary | |
|---|---|
static boolean |
containsAny(String s,
String[] terms)
Tests to see if the given string contains any of the given terms. |
static boolean |
containsAnyIgnoreCase(String s,
String[] terms)
Tests to see if the given string contains any of the given terms. |
static boolean |
endsWithAny(String s,
String[] terms)
Tests to see if the given string ends with any of the given terms. |
static boolean |
endsWithAnyIgnoreCase(String s,
String[] terms)
Tests to see if the given string ends with any of the given terms. |
static boolean |
equalsAny(String s,
String[] terms)
Tests to see if the given string equals any of the given terms. |
static boolean |
equalsAnyIgnoreCase(String s,
String[] terms)
Tests to see if the given string equals any of the given terms. |
static String |
escapeHTML(String s)
Replaces characters that may be confused by a HTML parser with their equivalent character entity references. |
static String |
escapeJavaLiteral(String s)
Replaces characters that are not allowed in a Java style string literal with their escape characters. |
static String |
escapeRegularExpressionLiteral(String s)
Escapes characters that have special meaning to regular expressions |
static String |
escapeSQL(String s)
Replaces characters that may be confused by an SQL parser with their equivalent escape characters. |
static Pattern |
getContainsAnyIgnoreCasePattern(String[] terms)
Compile a pattern that can will match a string if the string contains any of the given terms. |
static Pattern |
getContainsAnyPattern(String[] terms)
Compile a pattern that can will match a string if the string contains any of the given terms. |
static Pattern |
getEndsWithAnyIgnoreCasePattern(String[] terms)
Compile a pattern that can will match a string if the string ends with any of the given terms. |
static Pattern |
getEndsWithAnyPattern(String[] terms)
Compile a pattern that can will match a string if the string ends with any of the given terms. |
static Pattern |
getEqualsAnyIgnoreCasePattern(String[] terms)
Compile a pattern that can will match a string if the string equals any of the given terms. |
static Pattern |
getEqualsAnyPattern(String[] terms)
Compile a pattern that can will match a string if the string equals any of the given terms. |
static Pattern |
getStartsWithAnyIgnoreCasePattern(String[] terms)
Compile a pattern that can will match a string if the string starts with any of the given terms. |
static Pattern |
getStartsWithAnyPattern(String[] terms)
Compile a pattern that can will match a string if the string starts with any of the given terms. |
static String |
join(String[] array)
Join all the elements of a string array into a single String. |
static String |
join(String[] array,
String delimiter)
Join all the elements of a string array into a single String. |
static String |
midpad(String s,
int length)
Pad the beginning and end of the given String with spaces until the String is of the given length. |
static String |
midpad(String s,
int length,
char c)
Pad the beginning and end of the given String with the given character until the result is the desired length. |
static String |
postpad(String s,
int length)
Pad the end of the given String with spaces until the String is of the given length. |
static String |
postpad(String s,
int length,
char c)
Append the given character to the String until the result is the desired length. |
static String |
prepad(String s,
int length)
Pad the beginning of the given String with spaces until the String is of the given length. |
static String |
prepad(String s,
int length,
char c)
Pre-pend the given character to the String until the result is the desired length. |
static String |
replace(String s,
String find,
String replace)
Replace occurrences of a substring. |
static String[] |
split(String s,
String delimiter)
Split the given String into tokens. |
static String[] |
splitIncludeDelimiters(String s,
String delimiter)
Split the given String into tokens. |
static boolean |
startsWithAny(String s,
String[] terms)
Tests to see if the given string starts with any of the given terms. |
static boolean |
startsWithAnyIgnoreCase(String s,
String[] terms)
Tests to see if the given string starts with any of the given terms. |
static String |
trim(String s,
String c)
Trim any of the characters contained in the second string from the beginning and end of the first. |
static String |
unescapeHTML(String s)
Turn any HTML escape entities in the string into characters and return the resulting string. |
| Methods inherited from class java.lang.Object |
|---|
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait |
| Constructor Detail |
|---|
public StringHelper()
| Method Detail |
|---|
public static String prepad(String s,
int length)
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.
public static String prepad(String s,
int length,
char c)
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.c - padding character.
public static String postpad(String s,
int length)
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.
public static String postpad(String s,
int length,
char c)
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.c - padding character.
public static String midpad(String s,
int length)
If the number of characters to pad is even, then the padding will be split evenly between the beginning and end, otherwise, the extra character will be added to the end.
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.
public static String midpad(String s,
int length,
char c)
If the number of characters to pad is even, then the padding will be split evenly between the beginning and end, otherwise, the extra character will be added to the end.
If a String is longer than the desired length, it will not be truncated, however no padding will be added.
NullPointerException - if s is null.s - String to be padded.length - desired length of result.c - padding character.
public static String[] split(String s,
String delimiter)
This method is meant to be similar to the split function in other programming languages but it does not use regular expressions. Rather the String is split on a single String literal.
Unlike java.util.StringTokenizer which accepts multiple character tokens as delimiters, the delimiter here is a single String literal.
Each null token is returned as an empty String. Delimiters are never returned as tokens.
If there is no delimiter because it is either empty or null, the only element in the result is the original String.
StringHelper.split("1-2-3", "-");
result: {"1","2","3"}
StringHelper.split("-1--2-", "-");
result: {"","1","","2",""}
StringHelper.split("123", "");
result: {"123"}
StringHelper.split("1-2---3----4", "--");
result: {"1-2","-3","","4"}
NullPointerException - if s is null.s - String to be split.delimiter - String literal on which to split.
public static String[] splitIncludeDelimiters(String s,
String delimiter)
This method is meant to be similar to the split function in other programming languages but it does not use regular expressions. Rather the String is split on a single String literal.
Unlike java.util.StringTokenizer which accepts multiple character tokens as delimiters, the delimiter here is a single String literal.
Each null token is returned as an empty String. Delimiters are never returned as tokens.
If there is no delimiter because it is either empty or null, the only element in the result is the original String.
StringHelper.split("1-2-3", "-");
result: {"1","-","2","-","3"}
StringHelper.split("-1--2-", "-");
result: {"","-","1","-","","-","2","-",""}
StringHelper.split("123", "");
result: {"123"}
StringHelper.split("1-2--3---4----5", "--");
result: {"1-2","--","3","--","-4","--","","--","5"}
NullPointerException - if s is null.s - String to be split.delimiter - String literal on which to split.
public static String join(String[] array)
If the given array empty an empty string will be returned. Null elements of the array are allowed and will be treated like empty Strings.
NullPointerException - if array is null.array - Array to be joined into a string.
public static String join(String[] array,
String delimiter)
If the given array empty an empty string will be returned. Null elements of the array are allowed and will be treated like empty Strings.
NullPointerException - if array or delimiter is null.array - Array to be joined into a string.delimiter - String to place between array elements.
public static String replace(String s,
String find,
String replace)
NullPointerException - if s is null.s - String to be modified.find - String to find.replace - String to replace.
public static String escapeHTML(String s)
Any data that will appear as text on a web page should be be escaped. This is especially important for data that comes from untrusted sources such as Internet users. A common mistake in CGI programming is to ask a user for data and then put that data on a web page. For example:
Server: What is your name? User: <b>Joe<b> Server: Hello Joe, WelcomeIf the name is put on the page without checking that it doesn't contain HTML code or without sanitizing that HTML code, the user could reformat the page, insert scripts, and control the the content on your web server.
This method will replace HTML characters such as > with their HTML entity reference (>) so that the html parser will be sure to interpret them as plain text rather than HTML or script.
This method should be used for both data to be displayed in text
in the html document, and data put in form elements. For example:
<html><body>This in not a <tag>
in HTML</body></html>
and
<form><input type="hidden" name="date" value="This data could
be "malicious""></form>
In the second example, the form data would be properly be resubmitted
to your cgi script in the URLEncoded format:
This data could be %22malicious%22
NullPointerException - if s is null.s - String to be escaped
public static String escapeSQL(String s)
Any data that will be put in an SQL query should be be escaped. This is especially important for data that comes from untrusted sources such as Internet users.
For example if you had the following SQL query:
"SELECT * FROM addresses WHERE name='" + name + "' AND private='N'"
Without this function a user could give " OR 1=1 OR ''='"
as their name causing the query to be:
"SELECT * FROM addresses WHERE name='' OR 1=1 OR ''='' AND private='N'"
which will give all addresses, including private ones.
Correct usage would be:
"SELECT * FROM addresses WHERE name='" + StringHelper.escapeSQL(name) + "' AND private='N'"
Another way to avoid this problem is to use a PreparedStatement with appropriate placeholders.
NullPointerException - if s is null.s - String to be escaped
public static String escapeJavaLiteral(String s)
NullPointerException - if s is null.s - String to be escaped
public static String trim(String s,
String c)
NullPointerException - if s is null.s - String to be trimmed.c - list of characters to trim from s.
public static String unescapeHTML(String s)
NullPointerException - if s is null.s - String to be unescaped.
public static String escapeRegularExpressionLiteral(String s)
NullPointerException - if s is null.s - String to be escaped
public static Pattern getContainsAnyPattern(String[] terms)
Usage:
boolean b = getContainsAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getEqualsAnyPattern(String[] terms)
Usage:
boolean b = getEqualsAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getStartsWithAnyPattern(String[] terms)
Usage:
boolean b = getStartsWithAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getEndsWithAnyPattern(String[] terms)
Usage:
boolean b = getEndsWithAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getContainsAnyIgnoreCasePattern(String[] terms)
Case is ignored when matching using Unicode case rules.
Usage:
boolean b = getContainsAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getEqualsAnyIgnoreCasePattern(String[] terms)
Case is ignored when matching using Unicode case rules.
Usage:
boolean b = getEqualsAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getStartsWithAnyIgnoreCasePattern(String[] terms)
Case is ignored when matching using Unicode case rules.
Usage:
boolean b = getStartsWithAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static Pattern getEndsWithAnyIgnoreCasePattern(String[] terms)
Case is ignored when matching using Unicode case rules.
Usage:
boolean b = getEndsWithAnyPattern(terms).matcher(s).matches();
If multiple strings are matched against the same set of terms, it is more efficient to reuse the pattern returned by this function.
terms - Array of search strings.
public static boolean containsAny(String s,
String[] terms)
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may contain any of the given terms.terms - list of substrings that may be contained in the given string.
StringHelper.getContainsAnyPattern(String[])
public static boolean equalsAny(String s,
String[] terms)
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may equal any of the given terms.terms - list of strings that may equal the given string.
StringHelper.getEqualsAnyPattern(String[])
public static boolean startsWithAny(String s,
String[] terms)
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may start with any of the given terms.terms - list of strings that may start with the given string.
StringHelper.getStartsWithAnyPattern(String[])
public static boolean endsWithAny(String s,
String[] terms)
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may end with any of the given terms.terms - list of strings that may end with the given string.
StringHelper.getEndsWithAnyPattern(String[])
public static boolean containsAnyIgnoreCase(String s,
String[] terms)
Case is ignored when matching using Unicode case rules.
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may contain any of the given terms.terms - list of substrings that may be contained in the given string.
StringHelper.getContainsAnyIgnoreCasePattern(String[])
public static boolean equalsAnyIgnoreCase(String s,
String[] terms)
Case is ignored when matching using Unicode case rules.
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may equal any of the given terms.terms - list of strings that may equal the given string.
StringHelper.getEqualsAnyIgnoreCasePattern(String[])
public static boolean startsWithAnyIgnoreCase(String s,
String[] terms)
Case is ignored when matching using Unicode case rules.
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may start with any of the given terms.terms - list of strings that may start with the given string.
StringHelper.getStartsWithAnyIgnoreCasePattern(String[])
public static boolean endsWithAnyIgnoreCase(String s,
String[] terms)
Case is ignored when matching using Unicode case rules.
This implementation is more efficient than the brute force approach of testing the string against each of the terms. It instead compiles a single regular expression that can test all the terms at once, and uses that expression against the string.
This is a convenience method. If multiple strings are tested against the same set of terms, it is more efficient not to compile the regular expression multiple times.
s - String that may end with any of the given terms.terms - list of strings that may end with the given string.
StringHelper.getEndsWithAnyIgnoreCasePattern(String[])
|
Luky Library - 4.1.1 (20061117-1148) | |||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | |||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | |||||||||